

Grâce à ses services managés, le cloud promet de réduire considérablement le temps consacré aux tâches d’exploitation, offrant ainsi la possibilité de se concentrer pleinement sur le développement de son produit.
Néanmoins, au-delà de la supervision et de la gestion des incidents, il subsiste un certain nombre de tâches récurrentes qu’il faut intégrer dans les responsabilités de ses équipes, faute d’accumuler de la dette technique et de devoir gérer dans l’urgence des points facilement anticipables.
Je vous propose ici quelques un de ces écueils, ainsi que des approches pour les aborder avec plus de sérénité.
Infrastructure as Code et dépendances
Une infrastructure moderne repose souvent sur du code Terraform pour gérer les ressources cloud (réseau, bases de données, load balancers, clusters Kubernetes, stockage, etc.), ainsi que sur des manifests Kubernetes (déploiements, etc.) ou des charts Helm.
Ce code et les objets qu’il gère sont régulièrement mis à jour par les développeurs et les éditeurs de solutions pour corriger des bugs et ajouter de nouvelles fonctionnalités.
Pour Terraform, il est nécessaire de maintenir à jour la version de Terraform elle-même, les providers qui implémentent les API du fournisseur de cloud, et les modules utilisés pour gérer les ressources standardisées.
Pour Kubernetes, ce sont les versions des charts et/ou des images Docker définies dans les manifests de ressources qui doivent évoluer. Bien que la mise à jour de l’application soit évidente sur un projet actif, il ne faut pas oublier toutes les ressources techniques déployées dans le cluster (agents de monitoring, outils de déploiement, contrôleurs Kubernetes, etc.).
Des outils comme Dependabot ou Renovate automatisent la détection des nouvelles versions disponibles et la création de merge requests pour les implémenter.
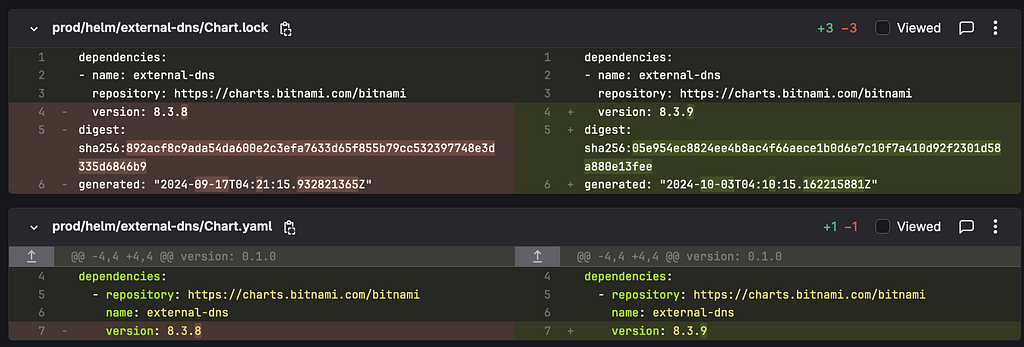
Cependant, il faut faire attention au volume de ces merge requests, car cela peut entraîner une “merge request fatigue”.
Mettre en place une stratégie de merge automatique (pour les mises à jour de type patch, par exemple) et de déploiement automatique (comme avec GitOps) permet de réduire les interventions humaines triviales.
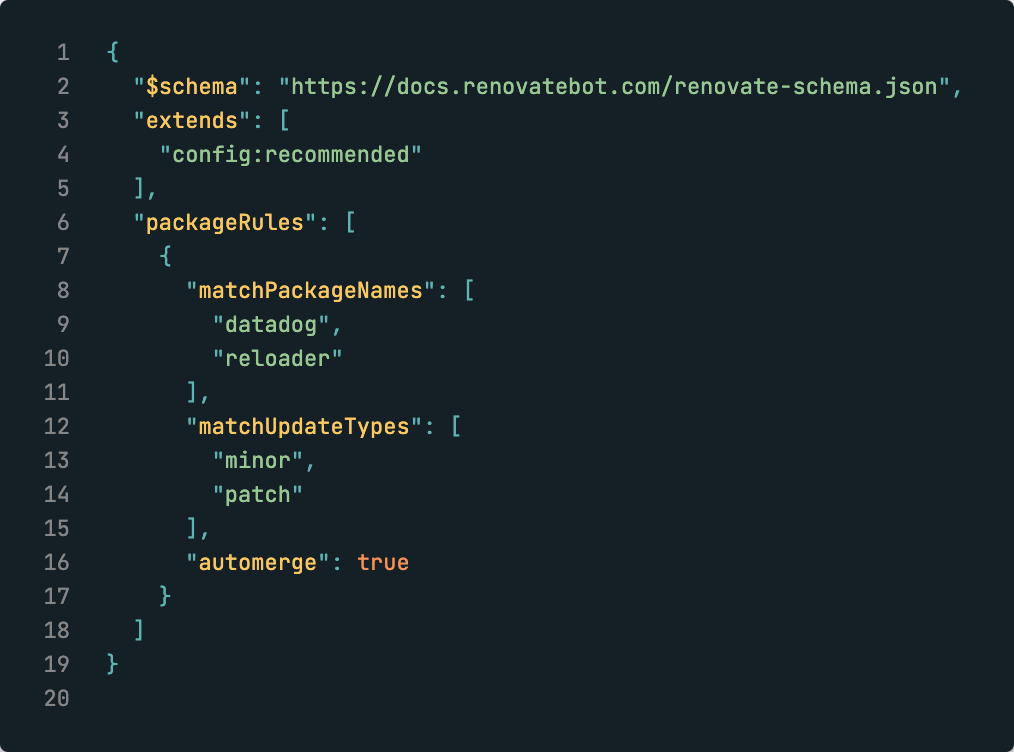
Cela permet de se concentrer sur l’analyse des changements potentiellement plus impactants.
Cycle de vie des services managés
Amazon RDS automatise les tâches indifférenciées de gestion des bases de données, telles que l’allocation, la configuration, les sauvegardes et l’application de correctifs (source https://aws.amazon.com/fr/rds/ )
Plus rien à faire ? Pas totalement !
Mettre à jour le moteur et l’OS
Le versions majeures de PostgreSQL sont supportées sur RDS pendant 4 à 5 ans, mais le début du développement d’un projet a peu de chances d’être aligné avec le cycle de releases d’AWS. De façon réaliste, on a donc souvent devant soi 2 ou 3 ans avant de devoir envisager une montée de version majeure.

En réalité, il faudra effectuer plusieurs mises à jour mineures au fil du temps.
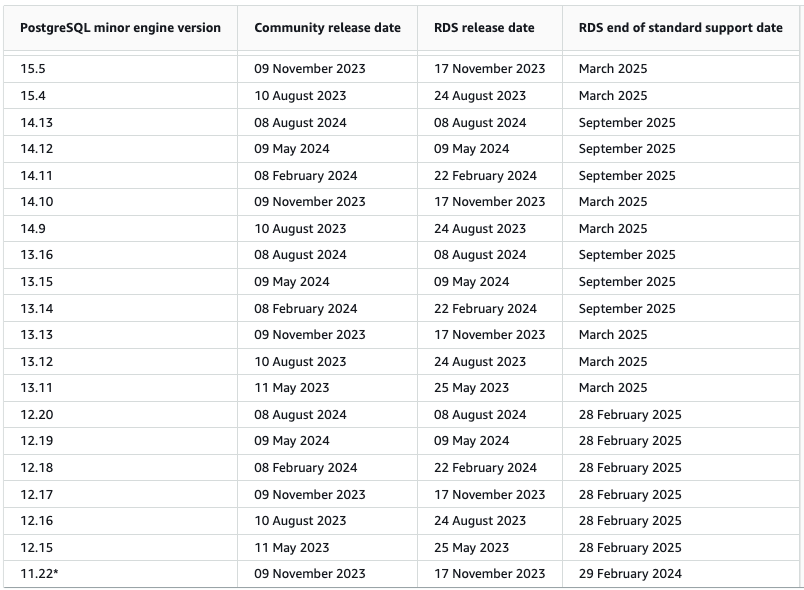
Les mises à jour mineures peuvent être appliquées automatiquement pendant des plages de maintenance planifiées pour minimiser les impacts. Bien que la plupart des frameworks modernes prennent en charge les mises à jour de PostgreSQL et MySQL de manière relativement transparente, ces opérations ne sont jamais sans risque.
Il est donc essentiel d’anticiper ces changements en les testant. A minima sur un environnement de développement, mais mieux : dans la chaîne d’intégration continue via des tests automatisés.
Une suite de tests de non-régression utilisant une infrastructure temporaire basée sur Docker Compose peut rapidement valider l’opération.
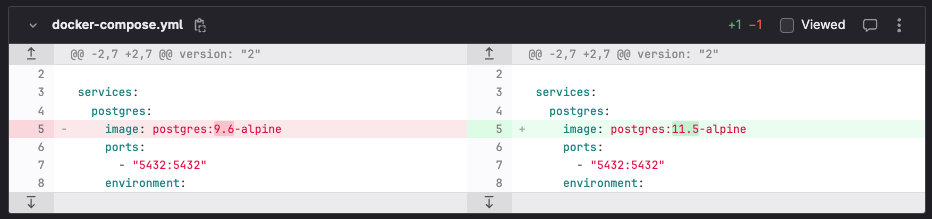
Au-delà du moteur de la base de données elle-même, AWS met également régulièrement à disposition des mises à jour de l’OS qu’il est recommandé (voir obligatoire) d’appliquer https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/OS_Updates.html.
Ces mises à jour doivent être validées pour être appliquées, ce qui pourra éventuellement être automatisé avec une fonction lambda.
Administrer les données
A mi-chemin entre le capacity planning et l’administration, il est également important de surveiller l’espace disque utilisé par les tables PostgreSQL et d’exécuter régulièrement pg_repack pour récupérer l’espace disque inutilisé.
Cette opération doit être effectuée régulièrement afin de garantir que la base dispose de suffisamment d’espace disque, tout en planifiant soigneusement l’ordre de traitement des tables ( https://aws.amazon.com/blogs/database/remove-bloat-from-amazon-aurora-and-rds-for-postgresql-with-pg_repack/ ).
Quelques autres exemples
Nous allons retrouver le même type de sujets pour de nombreux services :
- AWS Lambda a proposé le support de Node.js 14 pendant presque 3 ans, Node.js 16 pendant 2 ans, et devrait supporter Node.js 18 pendant environ 2,5 ans. Il convient donc de planifier les montées de versions applicatives avec les équipes de développement.
- Les services managés offrant Redis (Elasticache) et Elasticsearch / Opensearch nécessitent, de la même façon que RDS, l’application de mises à jour correctives et d’OS régulières à surveiller.
Comment aborder ces tâches ?
Tout d’abord en cataloguant chaque actif de sa plateforme : les repositories de code, les services déployés, les outils mobilisés.
Pour chacun de ces actifs, on détermine :
- Quel est son cycle de vie : s’agit-il d’une solution SaaS mise à jour en continu ? D’un service managé implémentant une version précise d’un logiciel (comme RDS pour PostgreSQL), et avec quelle politique de mise à jour ?
- Quelle est le rythme de mise à disposition des mises à jour, et de dépréciation des anciennes versions ?
- Par quel canal sont communiquées les mises à jour et échéances ? (flux RSS, trusted advisor AWS, …)
- Quelles sont les actions de maintenance préventives à effectuer (purge de données, pg_repack, …)
Une fois cette cartographie effectuée, on établit un RACI. L’objectif est d’éviter que ces opérations de maintenance, souvent rébarbatives mais essentielles, ne soient effectuées uniquement “quand on a le temps” en comptant sur la bonne volonté de chacun.
Enfin arrive l’étape de mise en œuvre, durant laquelle on pourra s’appuyer sur des solutions d’automatisation (comme renovate déjà évoqué plus haut, ou des solutions d’orchestration).
Pour terminer, et c’est probablement le point le plus important à retenir, ce process doit être initié dès les premières phases de build du projet. La dette technique commence dès la conception et elle ne s’applique pas qu’au code applicatif !
Anticiper la maintenance de son infrastructure AWS was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.