Introduction au NLP (Partie I)
Dans cette première partie introductive, nous définirons de manière général le concept de NLP et nous expliquerons certaines tâches courantes.

This article is available in english.
Introduction
Depuis les débuts de l’informatique, l’homme cherche à communiquer avec les machines. Si les nombreux langages de programmation permettent une forme d’échange entre l’homme et la machine, on aimerait que cette communication se fasse de façon plus naturelle. Pour que cela soit possible, il faut d’abord que la machine “comprenne” ce que l’utilisateur lui dit puis qu’elle soit capable de répondre d’une manière compréhensible par l’homme.
La discipline dernière ce processus s’appelle le Natural Language Processing (NLP) ou Traitement Automatique du Langage Naturel (TALN) en français. Elle étudie la compréhension, la manipulation et la génération du langage naturel par les machines. Par langage naturel, on entend le langage utilisé par les humains dans leur communication de tous les jours par opposition aux langages artificiels comme les langages de programmation ou les notations mathématiques.
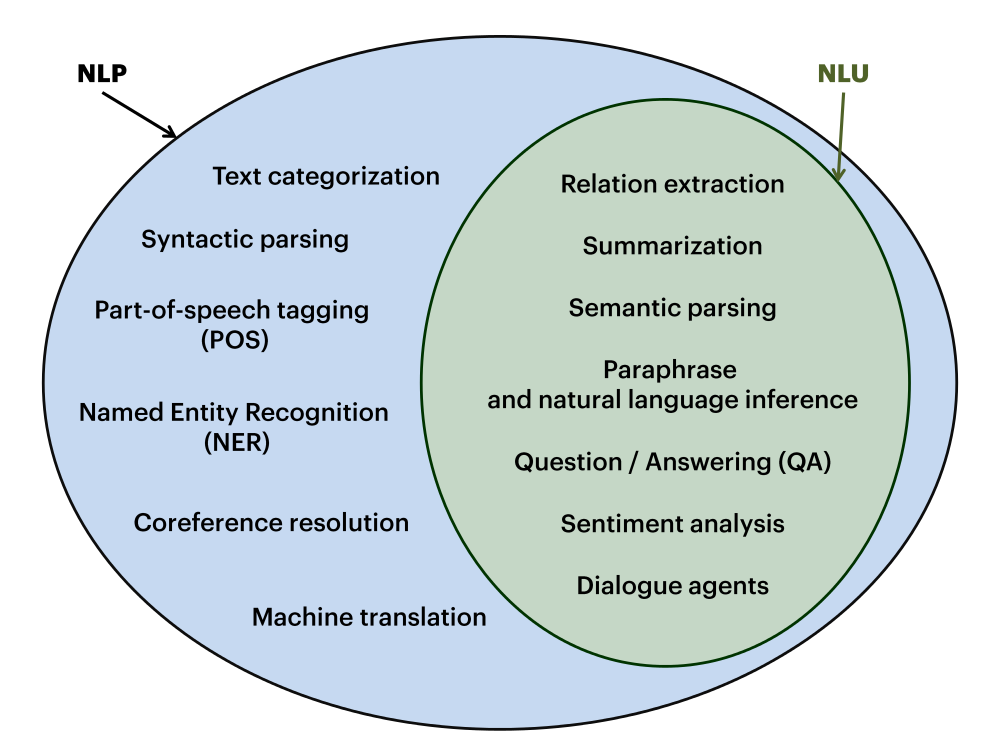
Le NLP est parfois confondu avec le NLU (en) dont l’expression est apparue plus récemment. Le NLU (Natural Language Understanding ou Compréhension du Langage Naturel en français) est en réalité un sous-domaine du NLP qui s’intéresse spécifiquement à la compréhension du langage écrit. Il regroupe des tâches comme l’analyse de sentiments (en), le résumé automatique de texte (en), les systèmes de questions-réponses (en), les agents conversationnels,….
Bref historique
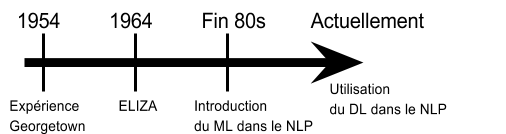
Le NLP est un champ de recherche qui commence avec les débuts de l’informatique moderne et prend réellement son essor ces dernières années. Son histoire débute dans les années 40 et 50. Elle se concentre alors essentiellement sur la traduction de phrases simples. On peut citer l’expérience Georgetown (en) en 1954 qui comportait la traduction complètement automatique de plus de soixante phrases russes en anglais.
Puis dans les années 60 et 70, on voit l’émergence des premiers chatbots comme ELIZA (1964). Mais c’est à la fin des années 80 que le NLP fait sa révolution avec l’introduction des algorithmes de _Machine Learning_ dans le traitement du langage et l’augmentation de la puissance informatique.
Actuellement, avec les technologies informatiques toujours plus perfectionnées et abordables, la quantité de données open source toujours plus importante et l’utilisation du _Deep Learning_, le NLP est en pleine expansion. Le Deep Learning est utilisé dans de nombreuses tâches du NLP entraînant une amélioration significative de leur performance. Il est également à l’origine du développement d’une méthode de transformation de mots en vecteurs numériques appelée _Word Embedding_. Cette technique est une réelle avancée car elle permet d’obtenir des vecteurs quantitatifs qui conservent la similarité contextuelle des mots.
Quelques tâches du NLP
Le tâches du NLP sont nombreuses et plus ou moins complexes. Parmi les tâches courantes, on peut citer la segmentation de texte. Il en existe différents degrés. Pour la segmentation d’un texte en phrases, on parlera de _Sentence Boundary Disambiguation_ (en) (SBD). Il s’agit alors de déterminer où commence et où s’arrête une phrase. Pour cela, on peut s’appuyer sur un ensemble de règles pré-établies ou déterminées par apprentissage à partir d’un texte.
# Input<br />
"Ceci est 1 première phrase. Puis j'en écris une seconde. pour finir en voilà une troisième sans mettre de majuscule"
# Output<br />
Ceci est 1 première phrase.<br />
Puis j'en écris une seconde.<br />
pour finir en voilà une troisième sans mettre de majuscule
# Input<br />
"Ceci est une première phrase Ceci en est une seconde mais il manque un point pour les séparer"
# Output<br />
Ceci est une première phrase Ceci en est une seconde mais il manque un point pour les séparer
On peut aussi fractionner un texte en unités plus petites appelées tokens, on parle alors de tokenisation (en). Les tokens peuvent être des mots, des n-grammes (groupe de n tokens consécutifs), des chiffres, des symboles et de la ponctuation.
# Input<br />
"Les tokens peuvent êtres des symboles $, des chiffres 7 et des mots!"
# Output<br />
['Les', 'tokens', 'peuvent', 'êtres', 'des', 'symboles', '$', ',', 'des', 'chiffres', '7', 'et', 'des', 'mots', '!']
Enfin, il est possible de faire de la segmentation de topics. Plusieurs approches sont possibles :
- Il peut s’agir d’une approche supervisée de classification de documents. Dans ce cas, les topics sont déjà connus et l’on entraîne un modèle de classification à partir d’un corpus de textes labellisés selon les topics pour ensuite utiliser ce modèle sur un nouvel ensemble de textes.
- Il peut également s’agir d’une approche non supervisée où l’on essaye de faire apparaître les topics principaux d’un ensemble de textes puis de relier les topics aux textes. On parle alors de _Topic Modeling_ (en).
Les tâches de classifications ne se limitent pas aux topics. Il est possible de classer des textes ou bien des phrases selon leur polarité (positif versus négatif) par exemple. La classification est une approche dite supervisée. Elle nécessite d’avoir des jeux de données labellisés, ce qui n’est pas toujours aisé à trouver. On peut alors utiliser des approches non supervisées de clustering qui vont permettre de regrouper des phrases ou des textes similaires sans avoir besoin d’un jeu de données labellisé.
D’autres tâches très courantes en NLP sont le _Part-Of-Speech Tagging_ (POS-Tagging ou étiquetage morpho-syntaxique en français) et le _Named-Entity Recognition_ (NER ou reconnaissance d’entités nommées en français). La première consiste à associer à chaque mot d’un texte sa classe morphosyntaxique (nom, verbe, adjectif…) à partir de son contexte et de connaissances lexicales.
La deuxième tâche permet de reconnaître dans un texte un certain type de concepts catégorisables dans des classes telles que noms de personnes, noms d’organisations ou d’entreprises, noms de lieux, quantités, distances, valeurs, dates….

Enfin parmi les tâches de NLP plus complexes, on peut citer la traduction automatique (Machine Translation, MT en anglais). La traduction automatique statistique (Statistical Machine Translation, SMT en anglais) repose sur des algorithmes prédictifs qui “apprennent” à partir d’un corpus parallèle, c’est-à-dire un ensemble de textes en plusieurs langues, en relation de traduction mutuelle. La traduction automatique neurale (Neural Machine Translation, NMT en anglais) s’appuie sur des algorithmes de Deep Learning.

Toutes les tâches citées précédemment se concentrent sur l’analyse et la compréhension du langage naturel mais un autre aspect important du NLP est la génération automatique de textes (Natural Language Generation, NLG en anglais). Le NLG permet notamment d’automatiser la génération de rapports, de résumés, de paraphrases, de réponses dans un système de dialogue….
Exemples d’applications courantes en NLP
Toutes ces différentes tâches permettent de développer des applications et outils dont beaucoup nous servent au quotidien. Comme précisé précédemment, la traduction automatique est utilisée par Google Translate mais aussi par beaucoup d’autres outils de traduction comme l’application mobile Microsoft Translator permettant de traduire des documents dans une soixantaine de langues différentes ou encore Skype Translator pour faciliter les conversations de groupes allant jusqu’à 100 interlocuteurs.
On assiste à l’heure actuelle à une multiplication des chatbots et assistants personnels (Google Now, Cortana, Siri). Ces technologies font appel à plusieurs tâches de NLP pour “comprendre” la demande de l’utilisateur et y répondre sous forme de langage naturel.
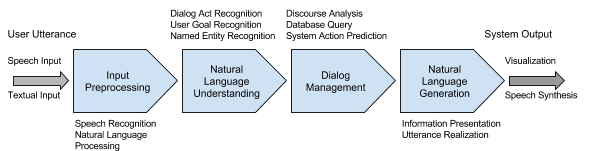
Schématiquement, dans un processus de système de dialogue (en), la déclaration de l’utilisateur (sous forme vocale ou textuelle) est pré-traitée par diverses méthodes de NLP. Le résultat du pré-traitement est ensuite analysé par une unité de NLU. Puis les informations sémantiques sont analysées par le “dialog manager” qui garde l’historique et l’état du dialogue et gère le flux général du dialogue. La dernière phase va permettre de générer une réponse à l’utilisateur sous une forme comprise par celui-ci.
La classification de textes permet de construire des détecteurs de spams ou faire de l’analyse de sentiments pouvant être utilisée par exemple dans la prédiction d’une élection, du succès ou non d’un film ou tout autre produit.
Le clustering permet de regrouper des documents similaires et peut être utilisé dans un système de recommandation d’articles par exemple.
Enfin de nombreuses tâches de NLP sont utiles pour faire de l’extraction d’informations. Le Topic Modeling par exemple, permet de déterminer les thèmes principaux d’un document sans avoir à le lire et d’en extraire des mots clefs.
Conclusion
Comme nous avons pu le voir dans cette première partie introductive, le NLP est un champ de recherche en plein développement. Sa grande complexité, liée à l’ambiguïté du langage naturel et à la très grande diversité des langues existantes, en fait un domaine très intéressant qui va continuer à évoluer et à s’améliorer. Cette évolution passe notamment par le développement de frameworks et l’enrichissement des données disponibles. Ces deux points seront abordés dans la seconde partie de l’introduction.
Bibliographie
- Page Wikipédia sur le NLP : https://en.wikipedia.org/wiki/History_of_natural_language_processing (en)
- Papier universitaire “Natural langage processing, a historical review” : https://www.cl.cam.ac.uk/archive/ksj21/histdw4.pdf (en)
- Article qui explique le Word Embedding de façon intuitive : https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/ (en)
- Article qui explique simplement les concepts de traduction automatique : https://interstices.info/jcms/nn_72253/la-traduction-automatique-statistique-comment-ca-marche
- Papier universitaire “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation” : https://arxiv.org/pdf/1609.08144.pdf (en)
Crédit images
L’ensemble des illustrations sont sous licence CC0 (en).