Stratégies d’optimisation des traversées dans Neo4j
L’histoire aurait pu s’arrêter après mon analyse de l’évolution des temps de traversées, mais je restais avec le problème des utilisateurs qui constataient quand même une dégradation des temps de réponse. Je pouvais difficilement me contenter de répondre que c’était pour le bien commun et un meilleur passage à l’échelle dans un futur plus ou moins lointain.
Pour reprendre le problème initial, le coût des opérations de l’API Neo4j core (Node::hasLabel, par exemple) a explosé par rapport à la version utilisant le cache et représente désormais une part importante du temps d’exécution. Que faire pour pallier cela ?

This article is available in English under “Optimization strategies for traversals in Neo4j”.
Cet article fait suite à « Performance des traversées dans Neo4j ».
Analyse préalable
La tâche est probablement limitée par des lectures sur disque, puisque l’on est dans une base de données. La meilleure des optimisations serait de supprimer une partie du travail effectué, parce qu’inutile, plutôt que d’essayer de l’accélérer.
Que fait exactement notre traversée ? Elle parcourt chaque nœud de l’arbre, la partie Evaluator vérifie s’il est du type B et si sa propriété vaut true et continue de toute manière le parcours, puis la partie PathExpander vérifie s’il est du type A ou B pour rechercher les relations sortantes du bon type. On a donc 2 ou 3 appels à Node::hasLabel par nœud, suivant qu’il est de type A ou B. On a également un appel à Node::getRelationships par nœud pour étendre la traversée, et un appel à Node::getProperty par nœud de type B. Difficile de faire moins fonctionnellement, il n’y a donc malheureusement rien à couper.
Regardons avec un profiler comment est réparti le coût des appels à Node::hasLabel pour une traversée. J’utilise les différents modes de Yourkit pour explorer progressivement.
D’abord en mode CPU sampling, qui a un surcoût faible. Node::hasLabel (ou plus exactement son implémentation, NodeProxy::hasLabel) est alors mesurée comme contribuant 19 % à la traversée, et ses propres appels sont répartis comme suit :
- 16 % dans
OperationsFacade::labelGetForName, qui permet d’obtenir l’index du libellé à partir de son nom ; - 84 % dans
OperationsFacade::nodeHasLabel, lui-même appelant une unique autre méthode, qui en appelle une unique autre, etc. avec un coût relatif décroissant (chaque méthode à son coût propre, en plus du coût de ce qu’elle appelle). On finit par arriver sur des méthodes avec des noms tels queNodeStore::loadRecordouMuninnReadPageCursor::next, ça ressemble effectivement à de la lecture sur disque (load, read page), jusque là tout va bien.

Utilisons ensuite le mode CPU tracing, plus invasif, mais permettant d’obtenir le nombre d’appels et de mesurer plus finement le temps d’exécution des méthodes. Node::hasLabel est alors à 28 % de la traversée (l’observation influe sur la mesure), et la répartition de son coût est :
- 7 % dans
OperationsFacade::labelGetForName; - 73 % dans
OperationsFacade::nodeHasLabel; - 19 % de coût propre ;
- 1 % ailleurs.
Toujours de la lecture de données, mais on peut aussi constater qu’on a 3 millions d’appels à Node::hasLabel, soit entre 2 et 3 appels par nœud comme on s’y attendait.
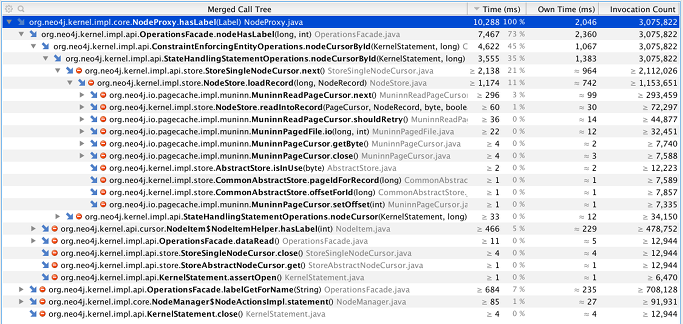
Pour finir, en associant le mode CPU tracing et la capture d’allocations, on obtient une vision du coût CPU combiné avec le flux mémoire, au prix d’un biais et d’un temps d’exécution plus importants. Node::hasLabel contribue maintenant à 42 % de la traversée :
- 2 % dans
OperationsFacade::labelGetForName; - 92 % dans
OperationsFacade::nodeHasLabel; - 6 % de coût propre.
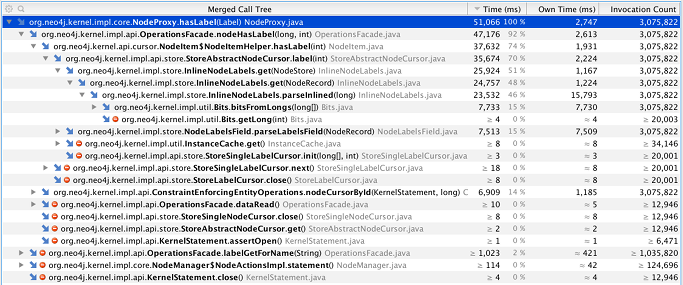
Évidemment, les lectures restent la principale composante du coût. Les allocations mesurées pour la requête représentent 76 Mo, répartis comme suit :
- 615 155 instances de
long[], soit 14 Mo ; - 307 591
InlineNodeLabelset autant deBits, soit 7 et 9 Mo respectivement ; - 139 822
int[], soit 3 Mo ; - 139 818
NodeProxy,NodeProxy$2etTraversalBranchImpl, soit 3, 3 et 5 Mo respectivement ; - 139 808
RelationshipType[],RelationshipConversionetRelationshipProxy, soit 3, 4 et 4 Mo respectivement ; - etc.

100 % des long[] créés dans la requête sont d’ailleurs créés sous Node::hasLabel ! Si on arrive à limiter le nombre d’appels à la méthode, on a donc un bon potentiel d’amélioration des allocations.
Optimisations possibles
Libellés
Avec 2 à 3 appels à Node::hasLabel par nœud, 1 seul à Node::getRelationships et 0 ou 1 à Node::getProperty, on ne peut pas faire grand chose pour une requête unique. Par contre, inspiré par un article de Max de Marzi (@maxdemarzi, Support Engineer chez Neo Technology) sur l’accélération de traversées, on peut explorer ce qu’il est possible de faire si l’on cache des données pour toutes les requêtes. De toute manière, dans la vraie application, nous avons plutôt 10 appels à Node::hasLabel en moyenne par nœud, et un cache local à la requête aurait plus de chances d’être amorti.
Je vais donc tenter de remplacer les lectures sur disque et les allocations associées par un autre type d’allocation, et voir si l’on y gagne.
L’approche la plus simple est de faire un cache avec une clé composée du nœud et du label, mais ça fait beaucoup d’objets pour accéder au final à un simple booléen, et il y a peut-être moyen de faire plus efficace. En regardant l’implémentation de Node::hasLabel (qui certes peut évoluer), on peut voir une simple itération sur les libellés jusqu’à trouver celui demandé : il n’y a pas de structure plus évoluée (index inversé, hash map, etc.) sous-jacente. Par conséquent, si un nœud a n libellés, la recherche d’un libellé va statistiquement parcourir n/2 nœuds avant de s’arrêter, et 2 appels à Node::hasLabel vont parcourir l’équivalent de n nœuds, ce qui correspond aussi à l’opération Node::getLabels. Bien sûr, Node::getLabels a un surcoût puisqu’elle crée la collection de libellés au lieu de simplement renvoyer un booléen, mais si on appelle plus de 2 fois en moyenne Node::hasLabel, utiliser Node::getLabels pour avoir tous les labels une fois pour toutes et les stocker dans une structure optimisée pour la recherche (un Set par exemple) peut s’avérer payant.
En fait, un Set, c’est bien, mais on peut aller encore plus loin dans l’exercice. Qu’est-ce qu’un Label ? L’API est très simple :
public interface Label {
String name();
}
Ça ressemble furieusement à un Enum, et c’est d’ailleurs un pattern recommandé pour l’implémentation :
enum Labels implements Label {
A, B, Root
}
Avec un Set, on pourrait specifiquement utiliser un EnumSet, plus efficace puisque basé sur la valeur ordinale de l’enum. En continuant dans cette direction, un libellé faisant partie de l’enum est équivalent à un index (sa valeur ordinale), qu’on peut encoder en un bit en utilisant du bit masking : le n-ième bit représente le fait d’avoir ou non le libellé numéro n, suivant qu’il est à 1 ou 0. C’est donc exactement ce que je vais faire : puisqu’on n’a que 3 libellés, on peut faire du bit masking sur un byte et cacher les libellés associés à un nœud (plus précisément, son identifiant Neo4j, un long) dans ce byte.
Nous utilisons déjà fastutil dans l’application pour avoir des collections de primitives (utilisant moins de mémoire que leurs équivalents objet), je vais donc utiliser une Long2ByteOpenHashMap pour représenter le cache.
Propriétés
Les propriétés pouvant être de nombreux types (booléen, numérique, chaîne de caractères, ou tableau d’un type précité), il n’y a guère d’autre solution que de cacher les propriétés accédées dans une Map<String, Object>.
Je joue quand même sur le fait qu’il n’y a qu’une seule propriété par nœud dans le démonstrateur, et j’utilise donc Collections::singletonMap pour stocker la première propriété, avant de repasser à une HashMap à partir de 2 ; ça occupe nettement moins de place en mémoire.
Relations
Cacher les relations est plus compliqué, puisque la solution la plus simple serait de cacher les identifiants des relations et de les recharger à la volée. Ça n’est pas si facile à implémenter, et les gains sont plus douteux sur le papier. Je décide donc de ne pas l’implémenter, d’autant que ça ne correspond pas vraiment à un scénario optimisable dans l’application, où l’on repasse très rarement plusieurs fois par le même chemin.
Mesure des effets
Tout ça est implémenté dans une nouvelle branche du démonstrateur, à l’aide de façades permettant d’activer les caches indépendamment (à travers des query parameters).
Toutes les mesures sont faites sur une instance Neo4j Enterprise 2.3.2 avec 4 Go de heap, et une traversée en mode depth-first. Neo4j tourne sur mon Mac Book Pro 15 pouces mi-2014 équipé d’un processeur Intel Core i7 2,2 GHz avec 4 cœurs, et de 16 Go de RAM, tournant sous OS X 10.11.4 (El Capitan) et avec une JVM Oracle 64 bits 1.8 u92.
Le gain obtenu avec le cache des libellés est plus important qu’avec celui des propriétés, et la combinaison des deux permet de gagner environ 30 % sur les temps de réponse.
| Scénario | Référence | Cache des libellés | Cache des propriétés | Tous les caches |
|---|---|---|---|---|
| Moyenne | 1540 | 1209 | 1387 | 1067 |
| 50 % | 1547 | 1207 | 1384 | 1053 |
| 90 % | 1693 | 1229 | 1427 | 1100 |
| 95 % | 1716 | 1241 | 1432 | 1192 |
| Maximum | 1757 | 1284 | 1447 | 1248 |
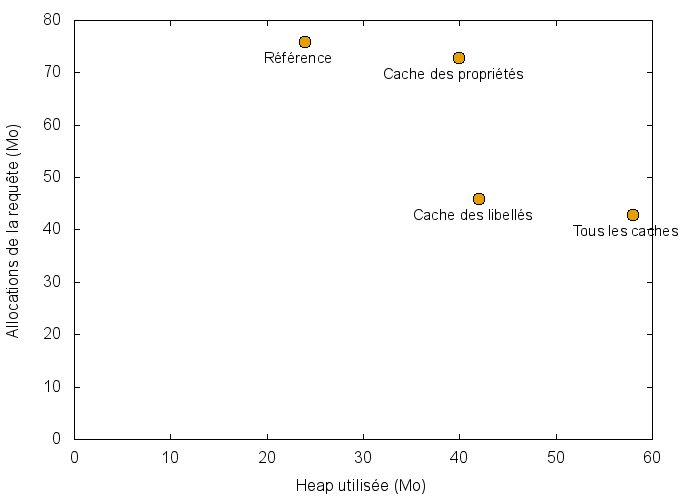
| Heap utilisée (Mo) | 24 | 42 | 40 | 58 |
| Allocations de la requête (Mo) | 76 | 46 | 73 | 43 |
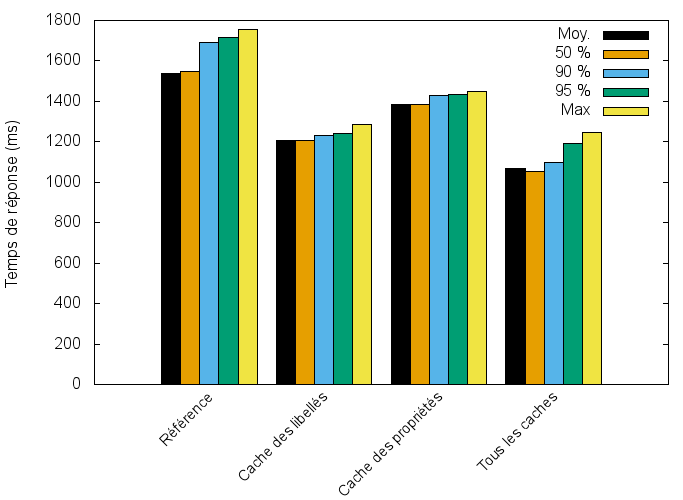
L’effet est donc largement positif, sans entraîner un accroissement de l’occupation mémoire inconsidérée. L’allocation des caches permanents lors de la toute première requête (18 Mo pour le cache des libellés, 16 Mo pour le cache des propriétés) est plus que largement compensée par la diminution des allocations d’une requête individuelle au-delà de la première requête, avec l’impact le plus important pour le cache des libellés qui permet d’éliminer 30 Mo d’allocations (près de 40 %), contre seulement 3 Mo pour le cache des propriétés. La pression mémoire est diminuée, il y a moins de garbage collections, moins de pauses, etc.
Et sans modifier le code ?
Une autre stratégie possible, quand on s’appuie sur une plate-forme, c’est de bénéficier des optimisations bas niveau de celle-ci, quand il y en a. Depuis notre migration vers la version 2.3, Neo4j 3.0 est devenue disponible. Il s’agit d’une nouvelle version majeure, avec son lot d’évolutions fonctionnelles et techniques. Indépendamment du planning de migration de notre application vers la 3.0, on peut regarder ses apports grâce au démonstrateur.
Par ailleurs, nous nous appuyons sur une seconde plate-forme : la JVM. J’avais d’ailleurs négligé un point lors du passage de la version 2.1 à 2.3 : le garbage collector (GC) par défaut de Neo4j était passé de Concurrent Mark Sweep (CMS) à Garbage First (G1), et nous en avions également profité pour passer du JDK 7 au JDK 8. Or, même si G1 est supposé remplacer CMS, les résultats sont plutôt mitigés pour de nombreux utilisateurs (comme ElasticSearch ou ses utilisateurs par exemple), avec de nombreuses corrections de problèmes jusque dans les versions récentes du JDK. Le benchmark est synthétique et ne représente pas une situation de production, mais je vais quand même explorer l’impact de l’algorithme de GC.
Comme pour la comparaison entre les versions 2.1 et 2.3, le même jar contenant l’extension est donc déployé dans différentes versions de Neo4j Enterprise avec la même configuration : toujours 4 Go de heap, et une traversée en mode depth-first, sans aucun cache activé.
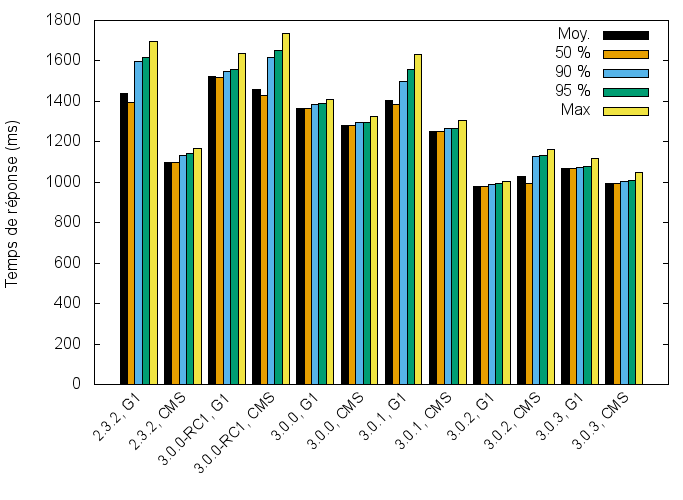
Si l’on se concentre sur les cas utilisant G1, une dégradation pouvait être observée avec la version 3.0.0-RC1 (Release Candidate 1), mais la version finale améliore au contraire légèrement les temps de réponse par rapport à 2.3.2. Un gain spectaculaire est surtout observé à partir de la version 3.0.2, avec des temps de réponse réduits d’environ 25 %. La version 3.0.3 réussit même à améliorer encore un peu le score.
Par contre, si on compare G1 et CMS, CMS donne de meilleurs temps de réponse dans la plupart des cas, avec notamment une différence énorme en version 2.3.2 où les temps sont inférieurs de presque 25 %. L’écart ayant quasiment disparu en 3.0.2 et 3.0.3, on peut imaginer que l’amélioration des performances est en partie due à une réduction des allocations, ce qui diminue la part du garbage collector dans l’équation.
| Version | 2.3.2 | 3.0.0 RC1 | 3.0.0 | 3.0.1 | 3.0.2 | 3.0.3 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GC | G1 | CMS | G1 | CMS | G1 | CMS | G1 | CMS | G1 | CMS | G1 | CMS |
| Moyenne | 1438 | 1100 | 1521 | 1461 | 1367 | 1281 | 1406 | 1252 | 980 | 1027 | 1067 | 993 |
| 50 % | 1395 | 1098 | 1517 | 1429 | 1365 | 1282 | 1386 | 1251 | 980 | 992 | 1067 | 992 |
| 90 % | 1596 | 1131 | 1548 | 1616 | 1384 | 1294 | 1498 | 1264 | 990 | 1125 | 1075 | 1006 |
| 95 % | 1619 | 1140 | 1556 | 1654 | 1391 | 1298 | 1560 | 1268 | 994 | 1134 | 1078 | 1010 |
| Maximum | 1694 | 1168 | 1637 | 1735 | 1409 | 1323 | 1630 | 1305 | 1006 | 1163 | 1120 | 1049 |
Je ne suis pas (encore) allé jusqu’à comparer les différentes versions avec un profiler, mais manifestement les ingénieurs de Neo Technology ont bien travaillé, même sur des versions mineures 3.0.x.
Conclusion
Après ces résultats, j’ai appliqué le même type de cache des libellés dans la vraie application, avec quelques variations :
- il utilise un type de donnée plus large que
byte(car nous avons plus de 8 libellés) ; - le cache est local à la requête HTTP et non plus permanent comme dans le démonstrateur.
Rendre le cache local permet de ne pas avoir à gérer son invalidation, son occupation mémoire, ou les pauses induites. Il reste un gain car pour un seul nœud, on peut avoir jusqu’à une dizaine de demandes pour savoir s’il a tel ou tel libellé (pour le classifier, savoir quelles relations suivre, le filtrer, etc.). Notamment, le gain en terme d’allocations est significatif. Au final, les temps de réponse ont été réduits de 23 %, les ramenant à un niveau acceptable même si supérieur à la mesure « parfaite » de Neo4j 2.2.
Enfin, la diminution des pauses de garbage collection grâce aux moindres allocations permet d’obtenir des temps de réponse plus stables, mais il ne faut pas non plus négliger l’algorithme de garbage collection lui-même. Un unique benchmark n’est cependant pas représentatif à cet égard, et il faudra plutôt comparer l’utilisation de G1 et CMS sur du trafic applicatif réel avant de faire un choix.